SQL SERVER介绍
数据库:数据库是“按照数据结构来组织、存储和管理数据的仓库”。是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合。
应用场景:在软件系统中无处不在,几乎所有的软件系统背后都有数据库,例如(淘宝,QQ,游戏等)。
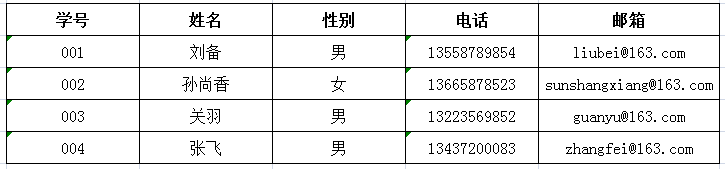
数据表展现形式: (二维表)
主流关系型数据库: SQL SERVER,MySQL,Oracle等。
数据库的安装:
(1)百度搜索”I tell you”,或者访问 https://msdn.itellyou.cn/
(2)选择合适的版本,下载安装。
打开数据库:
(1)启动服务:
【1】命令行启动;【2】SQL SERVER配置管理器;【3】Windows服务;
(2)打开SQL SERVER Management Studio,使用工具连接到数据库。
【1】Windows身份验证; 【2】SQL SERVER身份验证;
数据库基本操作:
(1)建库。
(2)建表。
(3)数据维护。
数据库的迁移:
(1)数据库的分离、附加;(分离和删除的区别在于硬盘上是否还留存有数据库文件)
(2)数据库的备份,还原;
(3)数据库脚本的保存;
建库建表
一、检查数据库名是否存在
如果需要创建数据库,可能会出现数据库名字重名的现象,我们可以使用如下代码查询数据库名是否存在,存在则删除此数据库。
--删除数据库 |
此代码检查数据库中是否存在”DBTEST”数据库,如果存在则删除此数据库,此处理方式最好只在学习阶段使用,在正式生产环境中慎用,操作不当可能会删除重要数据。
二、创建数据库
--创建数据库 |
以上代码创建”DBTEST”数据库,并且分别使用on和log on规定了数据文件和日志文件的信息。
创建数据库也可以按照如下简单语法来创建:
create database DBTEST |
如果按照上述方式创建数据库,数据库的数据文件和日志文件的相关信息,全部采取默认值。
三、建表
使用数据库和删除数据表:
use DBTEST --切换当前数据库为DBTEST |
创建数据表语法:
create table 表名 |
其中数据类型,我们在后面用到什么类型,在介绍什么类型,有的类型可以不填写长度。
创建数据表示例(部门表,职级表,员工信息表):
--创建部门表 |
字符串类型比较:
char:定长,例如 char(10),不论你存储的数据是否达到了10个字节,都要占去10个字节的空间 。
varchar:变长,例如varchar(10),并不代表一定占用10个字节,而代表最多占用10个字节。最大长度8000,也可以使用varchar(max)表示2G以内的数据,但存储机制会和text一样,效率会降低。
text:长文本, 最大长度为2^31-1(2,147,483,647)个字符 。
nchar,nvarchar,ntext:名字前面多了一个n, 它表示存储的是Unicode数据类型的字符,区别varchar(100)可以存储100个英文字母或者50个汉字,而nvarchar(100)可以存储100个英文字母,也可以存储100个汉字。
--创建职级表,rank为系统关键字,此处使用[]代表自定义名字,而非系统关键字 |
--创建员工信息表 |
修改表结构
(1)如需在表中添加列,请使用下面的语法:
ALTER TABLE table_name |
例如该员工表添加一列员工邮箱:
alter table People |
(2)如需在表中删除列,请使用下面的语法:
ALTER TABLE table_name |
例如删除员工表中的邮箱这一列
alter table People |
(3)如需改变表中列的数据类型,请使用下列语法:
ALTER TABLE table_name |
例如需要改变邮箱列的数据类型为varchar(100)
alter table People |
五、删除添加约束
删除约束语法:
if exists(select * from sysobjects where name=约束名) |
添加约束语法:
--添加主键约束 |
插入数据
一、向部门表插入数据
标准语法:
insert into Department(DepartmentName,DepartmentRemark) |
简写语法:(省略字段名称)
insert into Department values('行政部','公司主管行政工作的部门') |
此写法在给字段赋值的时候,必须保证顺序和数据表结构中字段顺序完全一致,不推荐使用此种写法,因为数据表结构变化的时候,数据会出错或产生错误数据。
一次插入多行数据:
insert into Department(DepartmentName,DepartmentRemark) |
二、向职级表插入数据
insert into [Rank](RankName,RankRemark) |
三、向员工表插入数据
insert into People(DepartmentId,RankId,PeopleName,PeopleSex,PeopleBirth, |
其中DepartmentId,RankId,PeopleSalary均为数字类型,在赋值的时候不需要添加单引号,而其它类型需要添加单引号。
四、查询数据是否插入成功
select * from Department |
修改和删除数据
一、修改数据示例
工资普调,为每个员工+500 元工资(批量修改)
update People set PeopleSalary = PeopleSalary + 500 |
将员工编号为8的工资+1000 元(根据条件修改)
update People set PeopleSalary = PeopleSalary + 1000 WHERE PeopleId = 8 |
将软件部(部门编号已知=1)所有员工工资低于1万的全部调整成1 万(根据多条件修改)
update People set PEOPLESALARY = 10000 WHERE DepartmentId=1 and PEOPLESALARY < 10000 |
修改刘备工资为以前的2 倍,并且修改其地址为北京(同时修改多个字段)
UPDATE People SET PEOPLESALARY = PEOPLESALARY*2,PEOPLEADDRESS='北京' WHERE PEOPLENAME = '刘备' |
二、删除数据示例
删除员工表中所有数据
DELETE FROM People |
删除市场部(已知部门编号=3)中工资大于15000 的所有员工
DELETE FROM People WHERE DepartmentId = 3 and PEOPLESALARY > 15000 |
三、drop、truncate、delete区别
drop table:删除表对象,表数据、表结构、表对象都进行了删除。
delete和truncate table:删除表数据,表对象及表结构依然存在。
delete与truncate table的区别如下:
delete:
(1)可以删除表所有数据,也可以根据条件删除数据。
(2)如果有自动编号,删除后继续编号,例如delete删除表所有数据后,之前数据的自动编号是1,2,3,那么之后新增数据的编号从4开始。
truncate table:
(1)只能清空整个表数据,不能根据条件删除数据。
(2)如果有自动编号,清空表数据后重新编号,例如truncate table清空表所有数据后,之前数据的自动编号是1,2,3,那么之后新增数据的编号仍然从1开始。
基础查询
(1)查询所有行所有列
--查询所有的部门 |
(2)指定列查询(姓名,性别,月薪,电话)
SELECT PeopleName,PeopleSex,PeopleSalary,PeoplePhone from People |
(3)指定列查询,并自定义中文列名(姓名,性别,月薪,电话)
SELECT PeopleName 姓名,PeopleSex 性别,PeopleSalary 工资,PeoplePhone 电话 from People |
(4)查询公司员工所在城市(不需要重复数据)
select distinct PeopleAddress from People |
(5)假设工资普调10%,查询原始工资和调整后的工资,显示(姓名,性别,月薪,加薪后的月薪)(添加列查询)。
SELECT PeopleName 姓名,PeopleSex 性别,PeopleSalary 月薪,PeopleSalary*1.1 加薪后月薪 from People |
条件查询
SQL中常用运算符
=:等于,比较是否相等及赋值 |
查询示例:
(1)根据指定列(姓名,性别,月薪,电话)查询性别为女的员工信息,并自定义中文列名
SELECT PeopleName 姓名,PeopleSex 性别,PeopleSalary 工资,PeoplePhone 电话 from People |
(2)查询月薪大于等于10000 的员工信息( 单条件 )
select * from People where PeopleSalary >= 10000 |
(3)查询月薪大于等于10000 的女员工信息(多条件)
select * from People where PeopleSalary >= 10000 and PeopleSex = '女' |
(4)显示出出身年月在1980-1-1之后,而且月薪大于等于10000的女员工信息。
select * from People where PeopleBirth >= '1980-1-1' and PeopleSalary >= 10000 and PeopleSex = '女' |
(5)显示出月薪大于等于15000 的员工,或者月薪大于等于8000的女员工信息。
select * from People where PeopleSalary >= 15000 or (PeopleSalary >= 8000 and PeoPleSex = '女') |
(6)查询月薪在10000-20000 之间员工信息( 多条件 )
--方案一: |
(7)查询出地址在北京或者上海的员工信息
--方案一: |
(8)查询所有员工信息(根据工资排序,降序排列)
--order by: 排序 asc: 正序 desc: 倒序 |
(9)显示所有的员工信息,按照名字的长度进行倒序排列
select * from People order by len(PeopleName) desc |
(10)查询工资最高的5个人的信息
select top 5 * from People order by PeopleSalary desc |
(11)查询工资最高的10%的员工信息
select top 10 percent * from People order by PeopleSalary desc |
(12)查询出地址没有填写的员工信息
select * from People where PeopleAddress is null |
(13)查询出地址已经填写的员工信息
select * from People where PeopleAddress is not null |
(14)查询所有的80后员工信息
--方案一: |
(15)查询年龄在30-40 之间,并且工资在15000-30000 之间的员工信息
--方案一: |
(16)查询出巨蟹 6.22–7.22 的员工信息
select * from People where |
(17)查询工资比赵云高的人
select * from People where PeopleSalary > |
(18)查询出和赵云在同一个城市的人
select * from People where PEOPLEADDRESS = |
(19)查询出生肖为鼠的人员信息
select * from People where year(PeopleBirth) % 12 = 4 |
(20)查询所有员工信息,添加一列显示属相(鼠,牛,虎,兔,龙,蛇,马,羊,猴,鸡,狗,猪)
--方案一: |
模糊查询
模糊查询使用like关键字和通配符结合来实现,通配符具体含义如下:
%:代表匹配0个字符、1个字符或多个字符。 |
(1)查询姓刘的员工信息
select * from People where PeopleName like '刘%' |
(2)查询名字中含有 “ 尚 “ 的员工信息
select * from People where PeopleName like '%尚%' |
(3)显示名字中含有“尚”或者“史”的员工信息
select * from People where PeopleName like '%尚%' or PeopleName like '%史%' |
(4)查询姓刘的员工,名字是2个字
--方案一: |
(5)查询出名字最后一个字是香,名字一共三个字的员工信息
--方案一: |
(6)查询出电话号码开头138的员工信息
select * from People where PeoplePhone like '138%' |
(7)查询出电话号码开头138的员工信息,第4位可能是7,可能8 ,最后一个号码是5
select * from People where PeoplePhone like '138[7,8]%5' |
(8)查询出电话号码开头133的员工信息,第4位是2-5之间的数字 ,最后一个号码不是2和3
--方案一: |
聚合函数
SQL SERVER中聚合函数主要有:
count:求数量 |
一、聚合函数举例应用
(1)求员工总人数
select COUNT(*) 数量 from People |
(2)求最大值,求最高工资
select MAX(PeopleSalary) 最高工资 from People |
(3)求最小时,求最小工资
select MIN(PeopleSalary) 最低工资 from People |
(4)求和,求所有员工的工资总和
select SUM(PeopleSalary) 工资总和 from People |
(5)求平均值,求所有员工的平均工资
--方案一: |
ROUND函数用法:
round(num,len,[type]) |
(6)求数量,最大值,最小值,总和,平均值,在一行显示
select COUNT(*) 数量,MAX(PeopleSalary) 最高工资,MIN(PeopleSalary) 最低工资,SUM(PeopleSalary) 工资总和,AVG(PeopleSalary) 平均工资 from People |
(7)查询出武汉地区的员工人数,总工资,最高工资,最低工资和平均工资
select '武汉' 地区,COUNT(*) 数量,MAX(PeopleSalary) 最高工资,MIN(PeopleSalary) 最低工资 |
(8)求出工资比平均工资高的人员信息
select * from People where PeopleSalary > (select AVG(PeopleSalary) 平均工资 from People) |
(9)求数量,年龄最大值,年龄最小值,年龄总和,年龄平均值,在一行显示
--方案一: |
(10)计算出月薪在10000 以上的男性员工的最大年龄,最小年龄和平均年龄
--方案一: |
(11)统计出所在地在“武汉或上海”的所有女员工数量以及最大年龄,最小年龄和平均年龄
--方案一: |
(12)求出年龄比平均年龄高的人员信息
--方案一: |
二、补充-SQL中常用时间处理函数
GETDATE() 返回当前的日期和时间
DATEPART() 返回日期/时间的单独部分
DATEADD() 返回日期中添加或减去指定的时间间隔
DATEDIFF() 返回两个日期直接的时间
DATENAME() 返回指定日期的指定日期部分的整数
CONVERT() 返回不同格式的时间
示例:
select DATEDIFF(day, '2019-08-20', getDate()); --获取指定时间单位的差值 |
时间格式控制字符串:
| 名称 | 日期单位 | 缩写 |
|---|---|---|
| 年 | year | yyyy 或yy |
| 季度 | quarter | qq,q |
| 月 | month | mm,m |
| 一年中第几天 | dayofyear | dy,y |
| 日 | day | dd,d |
| 一年中第几周 | week | wk,ww |
| 星期 | weekday | dw |
| 小时 | Hour | hh |
| 分钟 | minute | mi,n |
| 秒 | second | ss,s |
| 毫秒 | millisecond | ms |
分组查询
(1)根据员工所在地区分组统计员工人数 ,员工工资总和 ,平均工资,最高工资和最低工资
--方案一:使用union(此方案需要知道所有的地区,分别查询出所有地区的数据,然后使用union拼接起来。) |
(2)根据员工所在地区分组统计员工人数,员工工资总和,平均工资,最高工资和最低工资,1985 年及以后出身的员工不参与统计。
select PeopleAddress 地区,COUNT(*) 人数,SUM(PeopleSalary) 工资总和, |
(3)根据员工所在地区分组统计员工人数,员工工资总和,平均工资,最高工资和最低工资,要求筛选出员工人数至少在2人及以上的记录,并且1985年及以后出身的员工不参与统计。
select PeopleAddress 地区,COUNT(*) 人数,SUM(PeopleSalary) 工资总和, |
多表查询
一、笛卡尔乘积
select * from People,Department |
此查询结果会将People表的所有数据和Department表的所有数据进行依次排列组合形成新的记录。例如People表有10条记录,Department表有3条记录,则排列组合之后查询结果会有10*3=30条记录。
二、简单多表查询
此种查询不符合主外建关系的数据不会被显示
查询员工信息,同时显示部门名称
select * from People,Department where People.DepartmentId = Department.DepartmentId |
查询员工信息,同时显示职级名称
select * from People,Rank where People.RankId = Rank.RankId |
查询员工信息,同时显示部门名称,职位名称
select * from People,Department,Rank |
三、内连接
此种查询不符合主外建关系的数据不会被显示
查询员工信息,同时显示部门名称
select * from People inner join Department on People.DepartmentId = Department.DepartmentId |
查询员工信息,同时显示职级名称
select * from People inner join Rank on People.RankId = Rank.RankId |
查询员工信息,同时显示部门名称,职位名称
select * from People |
三、外连接
外连接分为左外连接、右外连接和全外连接。
左外联接:以左表为主表显示全部数据,主外键关系找不到数据的地方null取代。
以下是左外连接的语法示例:
查询员工信息,同时显示部门名称
select * from People left join Department on People.DepartmentId = Department.DepartmentId |
查询员工信息,同时显示职级名称
select * from People left join Rank on People.RankId = Rank.RankId |
查询员工信息,同时显示部门名称,职位名称
select * from People |
右外连接(right join):右外连接和左外连接类似,A left join B == B right join A
全外连接(full join):两张表的所有数据无论是否符合主外键关系必须全部显示,不符合主外键关系的地方null取代。
四、多表查询综合示例
(1)查询出武汉地区所有的员工信息,要求显示部门名称以及员工的详细资料
select PeopleName 姓名,People.DepartmentId 部门编号 ,DepartmentName 部门名称, |
(2)查询出武汉地区所有的员工信息,要求显示部门名称,职级名称以及员工的详细资料
select PeopleName 姓名,DepartmentName 部门名称,RankName 职位名称, |
(3)根据部门分组统计员工人数,员工工资总和,平均工资,最高工资和最低工资。
--提示:在进行分组统计查询的时候添加二表联合查询。 |
(4)根据部门分组统计员工人数,员工工资总和,平均工资,最高工资和最低工资,平均工资在10000 以下的不参与统计,并且根据平均工资降序排列。
select DepartmentName 部门名称,COUNT(*) 人数,SUM(PeopleSalary) 工资总和, |
(5)根据部门名称,然后根据职位名称,分组统计员工人数,员工工资总和,平均工资,最高工资和最低工资
select DepartmentName 部门名称,RANKNAME 职级名称,COUNT(*) 人数,SUM(PeopleSalary) 工资总和, |
五、自连接
自连接:自己连接自己。
例如有如下结构和数据:
create table Dept |
如果要查询出所有部门信息,并且查询出自己的上级部门,查询结果如下:
--部门编号 部门名称 上级部门 |



