SQL优化
在工作的过程中,我们经常会在开发时或者开发做压力测试后需要做数据库优化,提高数据库性能。在我开发的工作经验中把数据库优化分为三层:
- 业务上的优化
- sql层的优化(包含索引优化)
- 硬件层优化(属于运维工作)
业务层优化
在表里有十几亿的数据并且我们已经分库分表,集群了和索引也已经优化最好了。我们需要查询数据就需要分页查。我在做项目中一般分页查询也主要做以下两种:
一种是在业务查询使用sql语句限制每次查询数目(count或limit),第二种是使用ES(elasticsearch分布式全文检索引擎)。
sql层的优化(主要)
我在sql层面优化的套路是:
执行计划包含的信息




开启慢查询
慢查询,顾名思义,执行很慢的查询。有多慢?超过 long_query_time 参数设定的时间阈值(默认10s),就被认为是慢的,是需要优化的。慢查询被记录在慢查询日志里。
然而,慢查询日志默认是不开启的,也就是说一般人没玩过这功能。如果你需要优化SQL语句,就可以开启这个功能,它可以让你很容易地知道哪些语句是需要优化的(想想一个SQL要10s就可怕)。
打开慢查询两种方法:
- 方式一:
修改配置文件 在 my.ini 增加几行: 主要是慢查询的定义时间(超过2秒就是慢查询),以及慢查询log日志记录( slow_query_log)

- 方式二:
通过命令数据库开启慢查询:

打开之后可以配合explain使用,然后对慢查询进行优化。
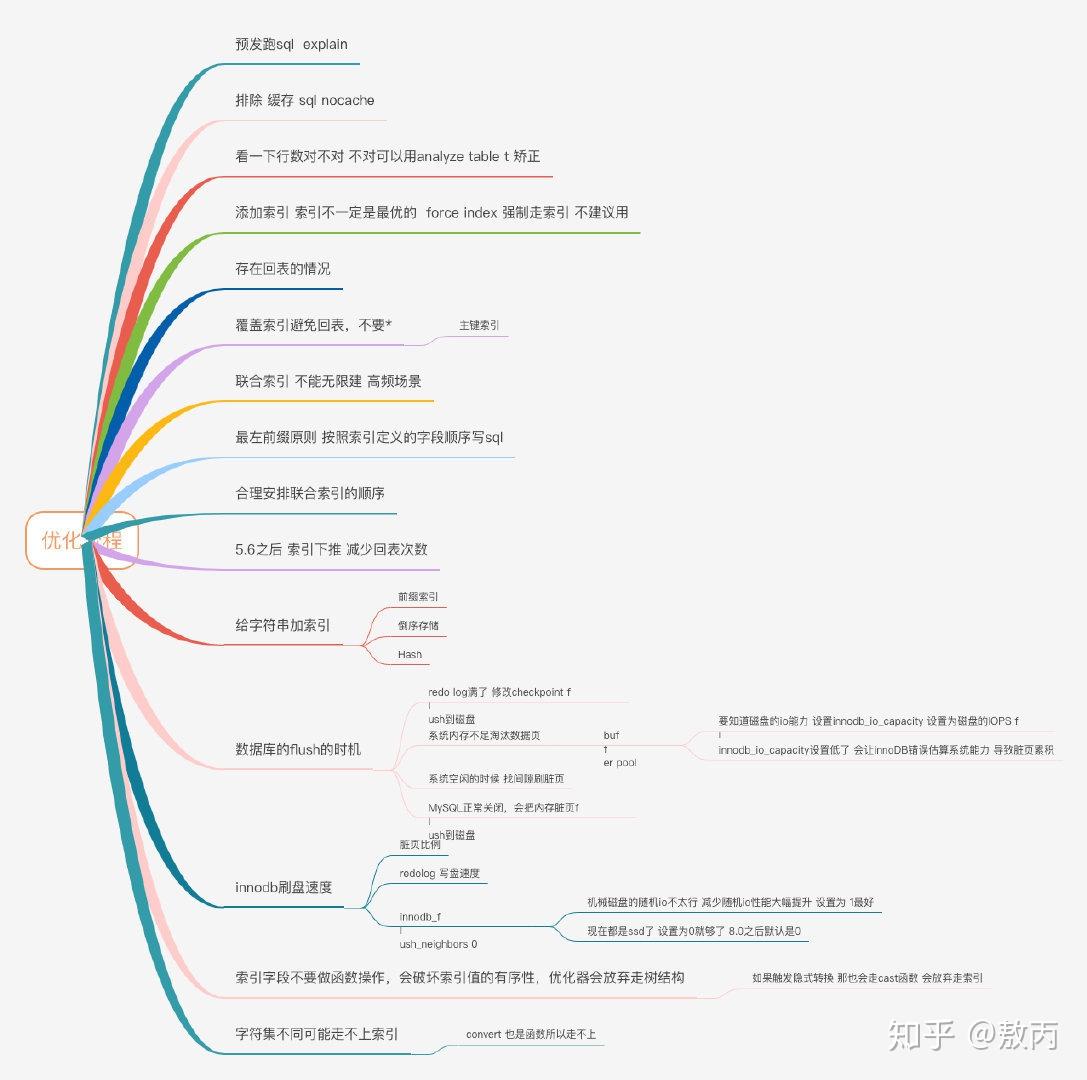
创建索引
- 要尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
- 在经常需要进行检索的字段上创建索引,一个表的索引数最好不要超过6个,索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。
- 创建联合索引,减少回表查询。(就是索引覆盖)
调整Where字句中的连接顺序
DBMS一般采用自下而上的顺序解析where字句,根据这个原理表连接最好写在其他where条件之前,那些可以过滤掉最大数量记录的条件必须写在WHERE子句的末尾。
例如:
(低效,执行时间156.3秒)
SELECT *
FROM EMP E
WHERE SAL > 50000
AND JOB = ‘MANAGER’
AND 25 < (SELECT COUNT(*) FROM EMP
WHERE MGR=E.EMPNO);
(高效,执行时间10.6秒)
SELECT *
FROM EMP E
WHERE 25 < (SELECT COUNT(*) FROM EMP
WHERE MGR=E.EMPNO)
AND SAL > 50000
AND JOB = ‘MANAGER’;
用where字句替换HAVING字句
避免使用HAVING字句,因为HAVING只会在检索出所有记录之后才对结果集进行过滤,而where则是在聚合前刷选记录,如果能通过where字句限制记录的数目,那就能减少这方面的开销。HAVING中的条件一般用于聚合函数的过滤,除此之外,应该将条件写在where字句中。
用union all替换union
当SQL语句需要union两个查询结果集合时,即使检索结果中不会有重复的记录,如果使用union这两个结果集同样会尝试进行合并,然后在输出最终结果前进行排序,因此如果可以判断检索结果中不会有重复的记录时候,应该用union all,这样效率就会因此得到提高。
只在必要的情况下才使用事务begin translation
SQL Server中一句SQL语句默认就是一个事务,在该语句执行完成后也是默认commit的。在该大事务提交之前,必然会阻塞别的语句,造成block很多。Begin tran使用的原则是,在保证数据一致性的前提下,begin tran 套住的SQL语句越少越好!有些情况下可以采用触发器同步数据,不一定要用begin tran。
尽量避免使用游标
尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。
用varchar/nvarchar 代替 char/nchar(SQLServer)
尽可能的使用 varchar/nvarchar 代替 char/nchar ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
查询select语句优化
任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描。
硬件层优化
我们使用数据库,不管是读操作还是写操作,最终都是要访问磁盘,所以说磁盘的性能决定了数据库的性能。一块PCIE固态硬盘的性能是普通机械硬盘的几十倍不止。其他运营知识还需要慢慢学习在工作中积累经验。
最后引用优秀B站up敖丙一张导图当做学习记录借鉴: